Llamactl Documentation¶
Welcome to the Llamactl documentation!
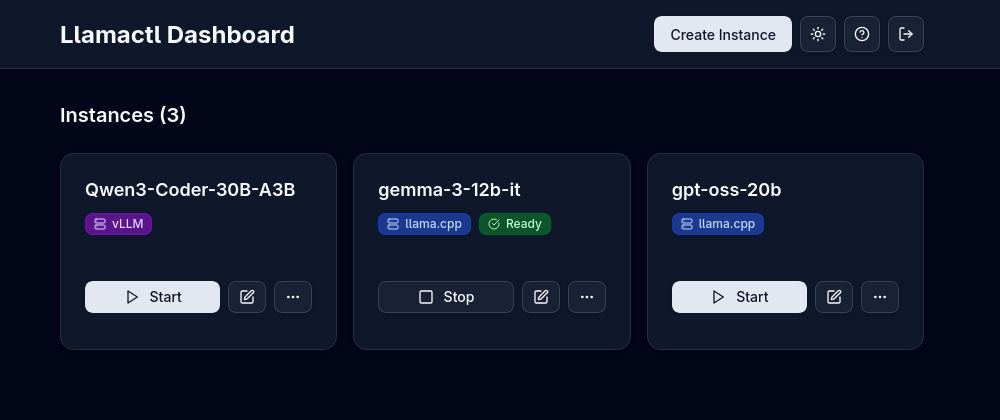
What is Llamactl?¶
Unified management and routing for llama.cpp, MLX and vLLM models with web dashboard.
Features¶
🚀 Easy Model Management
- Multiple Models Simultaneously: Run different models at the same time (7B for speed, 70B for quality)
- Smart Resource Management: Automatic idle timeout, LRU eviction, and configurable instance limits
- Web Dashboard: Modern React UI for managing instances, monitoring health, and viewing logs
🔗 Flexible Integration
- OpenAI API Compatible: Drop-in replacement - route requests to different models by instance name
- Multi-Backend Support: Native support for llama.cpp, MLX (Apple Silicon optimized), and vLLM
- Docker Ready: Run backends in containers with full GPU support
🌐 Distributed Deployment
- Remote Instances: Deploy instances on remote hosts
- Central Management: Manage everything from a single dashboard with automatic routing
Quick Links¶
- Installation Guide - Get Llamactl up and running
- Configuration Guide - Detailed configuration options
- Quick Start - Your first steps with Llamactl
- Managing Instances - Instance lifecycle management
- API Reference - Complete API documentation
Getting Help¶
If you need help or have questions:
- Check the Troubleshooting guide
- Visit the GitHub repository
- Review the Configuration Guide for advanced settings
License¶
MIT License - see the LICENSE file.